It seems like rendering could be done most efficiently if we somehow knew ahead of time what order objects are measured in depth, from closest to farthest. That way we would never have to sample a point in the buffer again (assuming no transparency). Is that right?
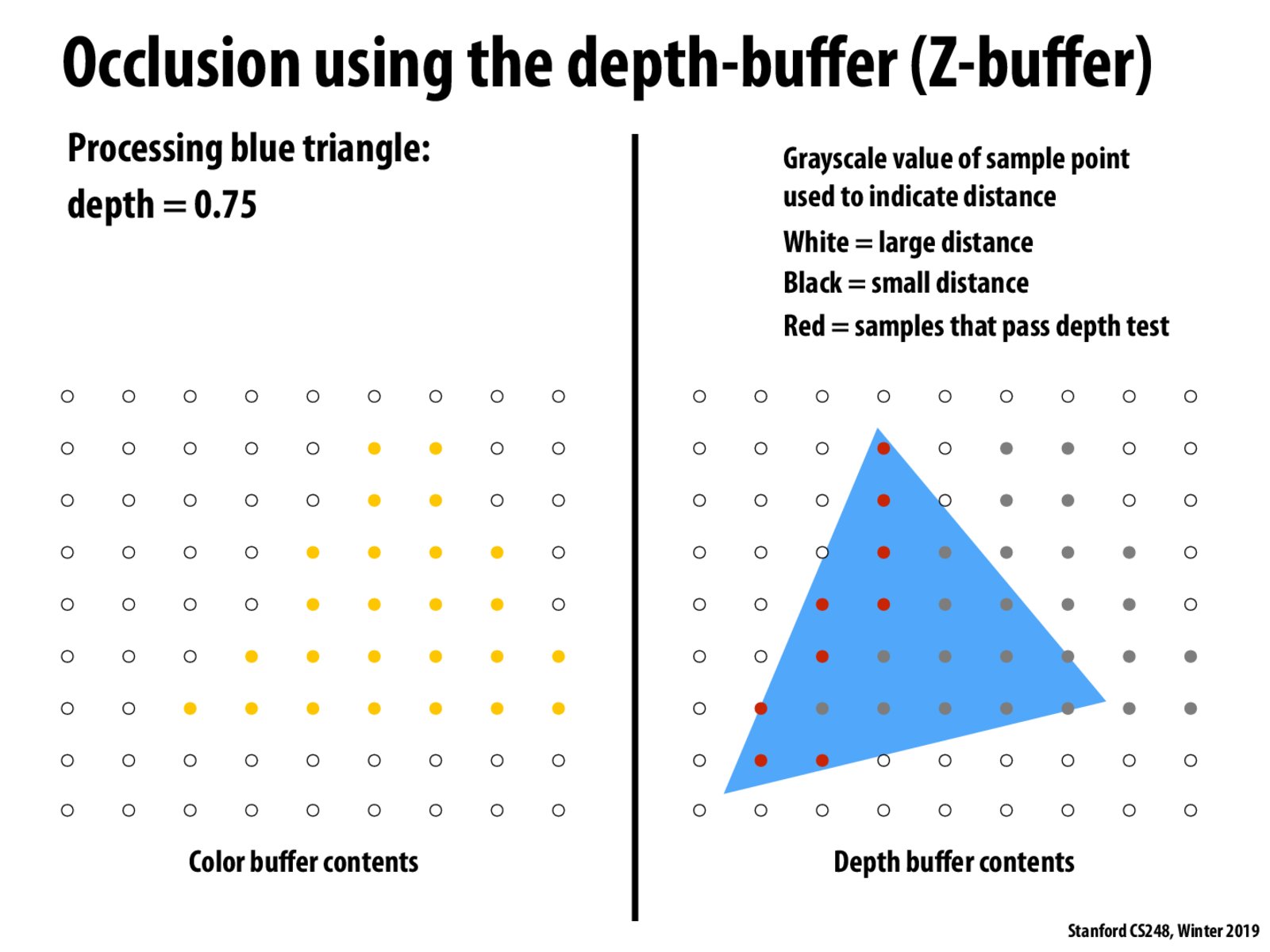
It seems like rendering could be done most efficiently if we somehow knew ahead of time what order objects are measured in depth, from closest to farthest. That way we would never have to sample a point in the buffer again (assuming no transparency). Is that right?