Is there a reason that we don't perform this optimization on non-mobile GPU's? I'm assuming there must be some sort of trade-off but not sure what it is
m11
Are all the GPU pipelines exactly the same? Or could there be GPUs that have a depth test completely dependent on the fragment processing step, so they cannot be optimized?
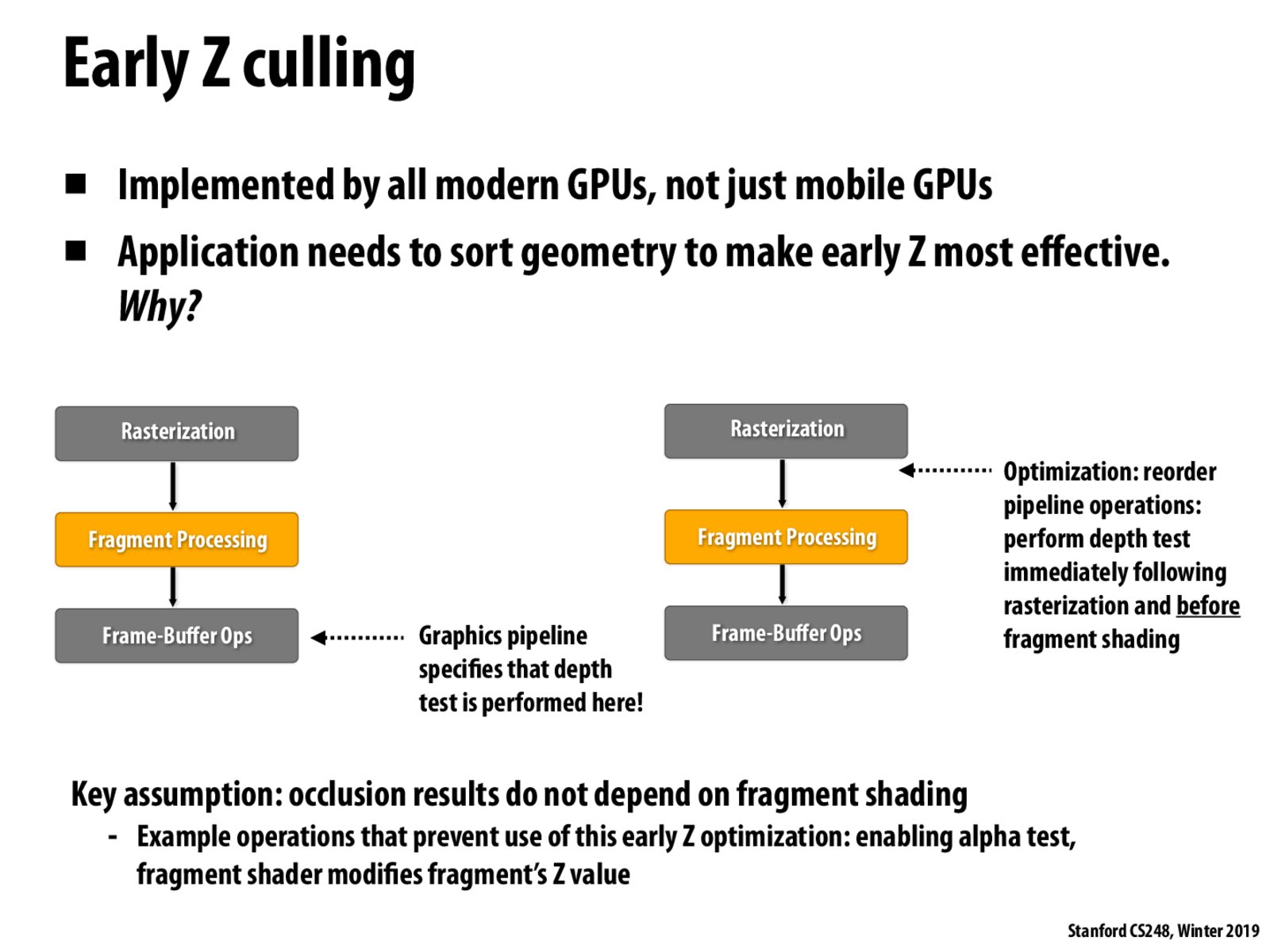
Is there a reason that we don't perform this optimization on non-mobile GPU's? I'm assuming there must be some sort of trade-off but not sure what it is
Are all the GPU pipelines exactly the same? Or could there be GPUs that have a depth test completely dependent on the fragment processing step, so they cannot be optimized?