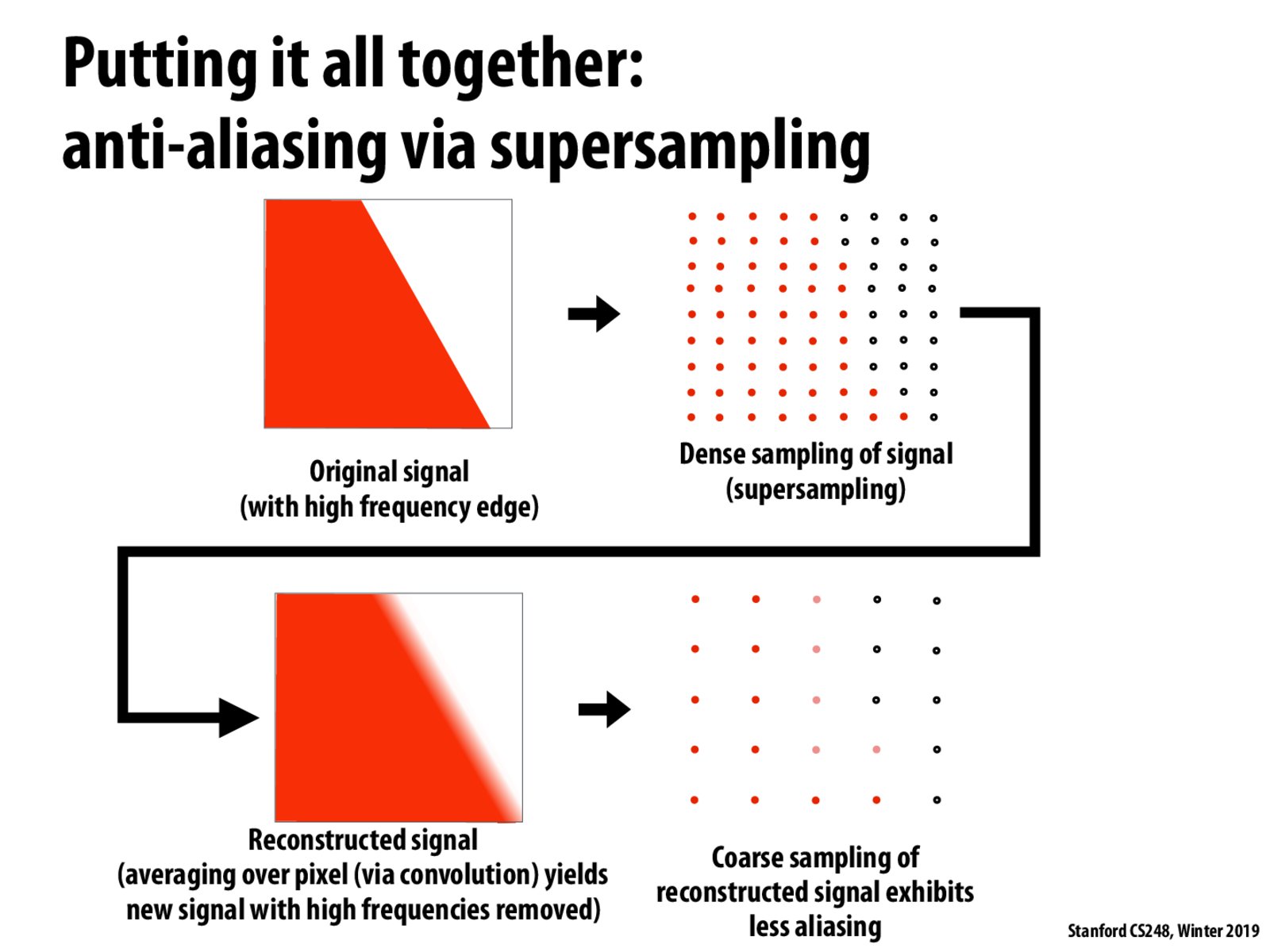
I'm confused about the difference between just using the convolution output as our final image, versus doing a second sampling? Is it that the convolution can be of different dimension than the one required for the final pixels?
Also, is there a heuristic for the appropriate size convolution, i.e. a mapping from Nyquist frequency to convolution dimensions?
THWG
I think it's the same if you do a 2d convolution on the spatial domain (of the supersampled signal) and then downsample it. But it's faster to do it in frequency domain due to the ease of parallelizing the computation.
amilich
Re: above, I also think that we need to do the second sampling to convert the figure into something that can be displayed on our graphics hardware (whereas the dense sampling can be in whatever form we want).
However, given our original discussion of supersampling in the first half of lecture, which resulted in the reconstructed signal displayed above, why do we need to go through these three steps above? Could we not just do the dense supersampling and average, as in the first algorithm? Or is this what is essentially going on in this slide too?
Gyro
Have the same question about what exactly the coarse sampling does?
nphirning
I'm similarly a bit confused about this. Specifically, I don't understand why you have to do the dense sampling. If you have the original signal in some nice, analytic form, is it not possible to do a convolution in a continuous way?
Erawn1
@nphirning My thought would be that having the original signal in an analytic form might be incredibly hard - imagine a 3D scene with reflections, refractions, transparencies, etc. We rely on bouncing light rays around the scene to figure out what each pixel actually comes out to (essentially sampling).
I'm confused about the difference between just using the convolution output as our final image, versus doing a second sampling? Is it that the convolution can be of different dimension than the one required for the final pixels?
Also, is there a heuristic for the appropriate size convolution, i.e. a mapping from Nyquist frequency to convolution dimensions?
I think it's the same if you do a 2d convolution on the spatial domain (of the supersampled signal) and then downsample it. But it's faster to do it in frequency domain due to the ease of parallelizing the computation.
Re: above, I also think that we need to do the second sampling to convert the figure into something that can be displayed on our graphics hardware (whereas the dense sampling can be in whatever form we want).
However, given our original discussion of supersampling in the first half of lecture, which resulted in the reconstructed signal displayed above, why do we need to go through these three steps above? Could we not just do the dense supersampling and average, as in the first algorithm? Or is this what is essentially going on in this slide too?
Have the same question about what exactly the coarse sampling does?
I'm similarly a bit confused about this. Specifically, I don't understand why you have to do the dense sampling. If you have the original signal in some nice, analytic form, is it not possible to do a convolution in a continuous way?
@nphirning My thought would be that having the original signal in an analytic form might be incredibly hard - imagine a 3D scene with reflections, refractions, transparencies, etc. We rely on bouncing light rays around the scene to figure out what each pixel actually comes out to (essentially sampling).